Exploring MapReduce for Large Collections of Phylogenetic Trees |
Journal
Navigation:
April 2014Week of Apr.27 - May 3rd: Bryce: I am trying some last minute ideas on the TreeZip code to see if I can get it to work on the larger datasets. Whether it works by Wednesday or not, I will have to be done, since that is when the semester-end writeup is due. Bryce, Rosemary and Nathaniel: Projects' Day was a success. Our poster turned out well (very large and colorful) and we presented to some pretty important people, including the Dean and the world-famous COL(R) Ragsdale. While we were a little nervous about presenting at first, but after running through it a few times it got to be much more fun and exciting. We also learned more about the project as the day went on by listening to our teammates talk through it with their own spectators. By the end of the day we understood MrsRF and phylogenetic trees better than we think we ever have before! Rosemary: I continued working on the CREU writeup by fixing the edits Dr. Matthews initially made. She sent it back to me one more time asking me to add information about our testing procedures to the "Process" section and to do a more thorough job describing the results and conclusions. I used a lot of the text from our published article. I submitted the final document on Friday. Week of Apr.13 - Apr.19: Nathaniel, Jorge, and Lisa: We continued to wrestle with integrating Hashbase into MrsRF++. They were able to get the output matrix to display numbers other than 7, but now they have to make sure that they are the correct numbers that are being outputted. The partial solution to the inaccuracy of the output matrix involved storing the various values that needed to be input to the matrix in a temporary variable. Previously, those values were written to an emit-intermediate, and since we removed the external executable, that was no longer a valid method of transposing the data. Bryce: I got TreeZip + MrsRF++ to work on the 5 tree, 5 taxa input. Now I need to make sure it works on the larger files and that it is able to run on both .trz and .tre files. Once we are sure it is completely correct and functional, we will run benchmarking and create new graphs for the data. Rosemary: I continued to work on the poster design this week. I completed several more figures and refined the wording in several areas. Now that TreeZip looks like it's coming together, we will soon have graphs of it to add to the poster. Also, if we are able to get Hashbase working, we will have to update the graphs comparing MrsRF++ to itself. Once we have this final information, the poster will be complete! Dr. Matthews showed us the format for the CREU writeup requirement. It is broken down into several easy-to-handle chunks, so we should be able to use a lot of what we have already written for previous papers. We'll compile all of the information in one document and then copy and paste the chunks into the appropriate boxes on the site. Week of Apr.6 - Apr.12: Nathaniel, Jorge, and Lisa: We are still working on integrating Hashbase into MrsRF++. We found that the reason they were getting the segmentation error was because the Malloc did not allocate enough memory for some for the data they were keeping. Now, MrsRF runs completely with the Hashbase code, but the output matrix is all 7's. Bryce I am still wrestling with logic errors. It seems that the correct values are being calculated (he checked them against the values in the original MrsRF++) but that they are not making it to the output matrix. Rosemary: Dr. Matthews and I went through two iterations of poster refining this week. During the first editing session, she made some adjustments to the organization and suggested several new figures (and fewer words). During the second session, we reviewed and corrected the figures I had made and discussed options for a few that I was not sure how to illustrate (namely, the one representing how trees are inferred). I also visited the ESG to pick up our tri-fold poster board. We have a lot of space to work with. March 2014Week of Mar.30-Apr.5: Nathaniel, Jorge, and Lisa: We are still working on integrating Hashbase into MrsRF++. We are currently wrestling with a segmentation fault/core dump issue. This error occurs in the section where lines are being printed, but it does not always happen in exactly the same place. We are concerned that the output of Hashbase is not being stored properly, or that the parallel processing is causing a problem. Bryce: I have managed to get the TreeZip code to compile and run. There is still a logic error, however, because the hashtable still contains all 1s. Rosemary I have used the basic layout and images from our ACMSE powerpoint to create a draft of our Projects Day poster. I'm not sure how to format it, so I got the Network Science Center layout from Willie to experiment. Dr. Matthews is not a fan of this template, however, so we will be changing some things in the coming weeks. We are also still not completely finished with our research, so it highly likely that we will have new background information, data, and images to add later on. Week of Mar.23-Mar.29: This week we focused on getting prepared for the ACMSE conference. For the second practice talk, Dr. Matthews had Nate take over from Bryce. The process of presenting and critiquing was much the same as it had been the first time around, and each time we heard Nate present, it got better. It was clear that he really understood what he was talking about. After Nate's practice talk, Dr. Matthews had a few critiques for the slides as well (adding some citations, for example). She also suggested adding several back up slides for the Word Count example and TreeZip because these seemed to be the most likely questions that someone would ask. Rosemary added and created some new figures for these slides and sent them to Nate for any final changes he wanted to make. The conference ran from Thursday through Saturday. Nate presented very well on Friday. Compared to other presenters, it was clear that the cadets had practiced/run through their presentations. Our slides had significantly less text than those of the other presenters. We did have a few people ask questions/throw out critiques, but the fact that they took the time/paid attention enough to make those comments makes us think that really were interested in our work. We had the chance to listen to a very interesting/engaging presentation during the banquet about Big Data. We will never look at a Coke machine the same way! Week of Mar.9-Mar.15: Nathaniel, Jorge, and Lisa: As we continued to work on integrating hashbase, we realized that the old code still contained the original call. We needed to change the code to actually call the integrated hashbase. Now re-entrance is still a possible issue, but we will not know until we finalize the code. Bryce and Rosemary: Bryce spent some time constructing the TreeZip shell for MrsRF++ phase 1. His main focus for this week was to determine which functions and data structures would be necessary to move forward. He also came up with a transcript based off of the initial slides and 6-page paper we submitted to ACMSE. He started talking through the first few slides before he met up with the rest of the group - they started out pretty rough, but as he practiced them more, he improved dramatically. When he presented to Dr. Matthews, Nate, and me formally, he was able to get through most of the slides pretty smoothly. Dr. Matthews still had some suggestions for him at the end, so we took notes on those and worked on incorporating them into the next iteration. After practicing the speech, we focused on significantly reducing the amount of text on the slides and increasing the number of pictures. Our goal was to have the slides support/highlight the topics of the talk (rather than BE the talk). At first it was difficult for Bryce to remember everything he needed to say, but after a little practice, the pictures and titles on each slide were enough to jog his memory about what he needed to cover. This method seems like it will be useful because the audience will receive the information in two forms - verbal and visual. Week of Mar.2-Mar.8: Nathaniel, Jorge, and Lisa: We continue to work on integrating Hashbase into MrsRF++. This week there were two sources of errors that dominated the troubleshooting. The first was capturing all the right header files in their proper directories. Since files were moved from the hashbase directory to the MrsRF directory, we had to ensure that all the files were updated to look in the right place. The second source of error was the ordering of the makefile, which was critical to compiling files in the right order such that all functions are defined before they are called by any other file. Testing will determine if including the hashbase as an executable will be more efficient. Rosemary, Bryce and Nathaniel: LTC Maymi observed while Dr. Matthews quizzed us on Tree Zip. Although we were a little shaky in some parts, our ability to answer Dr. Matthews questions demonstrated to LTC Maymi that we are on track with our project. After looking at several variations of the black, gray, and gold theme, Dr. Matthews and Rosemary decided on the theme they thought was best. The goal was to come up with something that looked professional and that represented West Point. Joey Hannigan (another student from USMA who will be presenting at the conference) will also use this template for his presentation at the ACMSE conference. We also officially registered for the ACMSE conference this week. Rosemary followed the general outline of the 6-page ACMSE paper submission to put together the first draft of the slides. The first version that was too wordy, and we ended up replacing most of the bullet points/explanations with pictures (so that the audience will not be focusing on the slides, but on Bryce, the speaker, instead). We refined the slide headings in an effort to guide Bryce during his presentation. February 2014Week of Feb.17-Feb.23: Nathaniel, Jorge, and Lisa: We are still working to integrate Hashbase into MrsRF++. The combined MrsRF++ and Hashbase makefiles will allow us to integrate hashbase, instead of using it as an executable. This part was simple once we determined the proper order of dependencies, but until then it was challenging to figure out how to satisfy one syntax (originally both files were written in different syntaxes). Having conducted a small test and training with AutoTools, Jorge had difficulty expanding that knowledge to our project. For one, our project was more complex, and secondly, our project used both C and C++ code. Instead we decided to manually create a makefile based on a more detailed tutorial of creating a makefile. Bryce and Rosemary: We have been doing a thorough rereading of the two papers, and as a result feel much more confident in our knowledge of TreeZip. In particular, we focused on the compression and decompression algorithms and the novelty of TreeZip (identical trees stored in Newick files can be written differently, but TreeZip is able to handle this without creating a larger file than necessary because it only records each unique bipartition once). Bryce, Nate, and Rosemary are working together to fill in any gaps we are having trouble with. Rereading the two papers carefully and closely examining the diagrams helped us understand TreeZip much better. Dr. Matthews also explained several key concepts to us last week that clarified a lot of the details that had been confusing us before. Working with the code more will definitely improve our understanding even more, but we seem to have a solid foundation. We submitted the rations requests for the ACMSE conference with plenty of time to spare, so there should not be any issues with getting them on time. Bryce will speak for our group at the conference, but the rest of us are still helping him to prepare. Rosemary began working on the template for the slides (that will be used by our group as well as by "Team Joey"). She was able to get higher resolution pictures of the EECS and USMA crests and will work those into the design. Until Bryce has a more exact idea of what he wants to say, the plan for the talk is to use the general outline of the paper that we submitted. There will most likely be more emphasis on the motivation/so what? portion of the presentation than there was in the original paper. Week of Feb.17-Feb.23: Jorge, Lisa and Nathaniel: We are still running into problems with integrating Hashbase into MrsRF++. The Makefile is still giving us problems, and all of our research and attempts to find solutions have failed miserably. We have reverted to attempting to update the old Makefile by hand, but we still have not met with significant success. However, we do not have any MPI compiler vs g++ compiler issues with the handmade Makefile. Bryce, Rosemary and Nathaniel: Dr. Matthews helped us locate the second Tree Zip paper. After an initial read-through of the two papers, we have a vague understanding of how Tree Zip works. We plan to read through them several more times. too. It is exciting to think that working Tree Zip into the code, because it has a hashtable already generated, can really speed up the MrsRF++ run time. We downloaded the Tree Zip code to the machine on Friday, so we have not had too much time to examine it yet. Based on our analysis, it should not take too long to implement. We plan to map out all of the important methods like we did originally for MrsRF. We plan to prepare for the quiz by exploring the code, reading the papers, discussing with the group, and drawing out diagrams for myself. Week of Feb.10-Feb.16: Nathaniel: I created a Python script that would generate sample data for MrsRF++. Given a file, the number of trees in the file, and the number of trees desired, the program randomly selects trees from the given data and produce a file with the desired number of trees. We hoped that testing MrsRF++ on a wider range of data sizes would yield better results. We used this code to generate large 66,612 tree and 40,000 tree data sets. However, these datasets threw errors when attempting to run the program and the results were discarded for the time being. Bryce, Nathaniel and Rosemary: Compared to our earlier results, the results we generated this week were closer to what we were hoping for. When compared to itself, MrsRF++ experiences significant speedups as more cores are added. We still, however, have not seen the improvement over MrsRF that we expected; our program is slightly faster thanks to updates to the use of unsigned short ints, but we hope that integrating Hashbase will lead to more dramatic improvements over the original version of the code. Rosemary:The final submission of the 5-page ACMSE paper was due on Friday. Because the original images we had constructed in Powerpoint for the 3-page submission looked fuzzy, we recreated them in an open-source program called InkScape. This program is similar to Paint, and after working with it for a little while, we were able to navigate the tools relatively easily. We worked on the Phase1, Phase2, and BipartitionExplanation images. Before submitting the final version of the ACMSE submission, all members of the group reviewed it for errors. We found a few grammar problems, but other than that we left it mostly the same. Lisa and Jorge: We continued work on the Makefile. This week we tried a few small changes by hand, but we focused our attention on the use of autotools. The problems we are currently encountering center around the use of MPI. Using the standard MPI compiler wrappers has proven unsuccessful, and attempting to include the appropriate libraries when using the standard g++ compiler has met with no significant success. Hopefully we will finally complete the Makefile next week. Week of Feb.3-Feb.9: Rosemary, Bryce and Nathaniel: We found the TreeZip paper online and have begun to read it. We are still a little fuzzy on the details, but so far we understand that TreeZip is a method of reducing the amount of memory necessary to store really HUGE trees. Dr. Matthews plans to quiz us on our understanding of the paper in the near future. Although we were not able to figure out why the program was no longer working on Bryce's branch, we found that MrsRF++ still ran without a segmentation fault on Nate's branch (as well as on Dr. Matthews' computer and the actual machine). That was a huge relief, although it is still frustrating that we were not able to discover the root of the problem on Bryce's branch. We got a response from ACMSE last week (more quickly than we was expecting!) telling us that our paper had been accepted to the conference! There was much joy and celebration. We also found out that we need to extend the paper to 6 pages. A couple of ways we can add length is by going more in depth into our results (comparing MrsRF++ not only to itself, but also to MrsRF original) and by adding more graphs. We may also be able to flesh out the other sections some more. Lisa and Jorge: We are still struggling to make any substantial progress on the Makefile. This week ended up consisting of conducting more research on how we can make the necessary changes to the Makefile. January 2014Week of Jan. 27-Feb.2: Bryce: We managed to make the change to using unsigned short ints in mrsrf-pq, and that solved our memory problems. The code was successfully run on the 567 and 150 tree datasets, and the results were added to the paper before it was submitted. After completing the submission to ACMSE, the code suddenly started producing a seg fault when we attempted to run it on Bryces branch. We have no idea what the source of this problem is, but the code runs without problem on Dr. Matthews machine. This situation is very odd because they are running exactly the same code (merged several times in order to confirm this). Jorge and Lisa: The attempts to improve the Makefile stalled again this week. We realized that we lack a solid enough understanding of what is happening and will therefore focus on research on Makefiles next week. Week of Jan. 20-Jan.26: Bryce and Nathaniel: We continued to chip away at the errors and segmentation faults in Phase 2 of MrsRF++ throughout the week. By the end of the week, we were able to run the program all the way through and achieve accurate results, when compared to the MrsRF results. The results, however, were not what we had expected. We had hoped that the MrsRF++ version of Phase 2 would be considerably faster than the original version's Phase 2, and for the most part it was. For the file 567-all.tre, though, adding more cores increased the program's running time instead of decreasing it. We think that this might be because we used 'int' instead of the original 'unsigned short int' to make the hashtable matrix. This situation seems particularly likely since we are seeing almost all the memory being used when we operate on this file. Rosemary: We revised the ACMSE paper several times last week with Dr. Matthews's help. We added several citations and examples and refined the writing and diagrams. Although we may make a few last-minute changes to the first part of the paper, our main focus will be on finishing up the results section before the paper is due tomorrow. Lisa and Jorge: We started to work on creating the Makefile for the combined mrsrf-pq and hahsbase file. This process is considerably more challenging than anticipated. The Makefile for hashbase was created using autotools, and is essentially unreadable. Therefore, it provides little help when attempting to used it to figure out what changes need to be made to our current mrsrf-pq Makefile. Week of Jan. 13-Jan.19: Last week, we discovered that the reason MrsRF++ was running on 2 cores when we asked it to run on 1 was because of the splitter function. We were able to make it work by adding a condition to the splitter function telling the program not to split the data if we entered a '1' for the number of cores. We continued working on converting MrsRF to MrsRF++. We have transplanted all of the necessary code into the new file and are now adjusting things to make sure the code compiles and gives us the correct results. We revised the ACMSE paper several times last week with Dr. Matthews's help. She suggested that we focus initially on the first two sections, the problem/motivation and the background/related work (especially since we do not yet have very good data for the results - we need to redo the results for Phase 1, and we still do not have any data for Phase 2). The paper contains the basic ideas and structure that we need for the final submission, but it could still use a lot of refining. The final version is due on Jan 27th. We are having difficulty with the hashbase integration. Attempting to debug errors is challenging since we have not updated the Makefile and have no way to compile the code at the moment. Week of Jan. 6-Jan.12: Last week we began working on the ACMSE submission. We started by cutting and pasting parts of what we had written in the end-of-semester report into the appropriate sections. We were having trouble getting the information down to three pages (the page limit of the submission) until Dr. Matthews pointed out that we were using too much detail. She offered us several other suggestions on how to improve it. In general, we need to step back and look at the project from an outsider's point of view. This will help us focus on the overarching themes and explain them in a way that helps someone who has never heard of phylogenetic trees understand what we are trying to accomplish. We have yet to discover the source of the error causing MrsRF++ to run on 2 cores when we ask it to run on 1 core. We tried a number of ideas to fix the problem, but nothing seemed to work. We tried changing the variable name (NUM_THREADS) to see if the code would still run and if not, find where it broke. This method did not help, so we tried running MrsRF by itself (instead of the mpi version), but this also was a dead end. One of the errors we saw led us to partitions.pl, which was called in the main function of mrsrf-pq, which had conditions determining how many cores the program would run on. This, however, was also not the issue because it was exactly the same as the partitions.pl that the original MrsRF code uses, which ran perfectly on 1 core. We are still trying to solve this problem. We also have begun working on converting Phase 2 to MrsRF++ using the same methods as we used for Phase 1. We are still in the early stages of this process. We also began work on integrating Hashbase into mrsrf-pq instead of having it as a stand-alone executable. When successful, this change should improve the speed of Phase 1. One of the major anticipated challenges is the conversion of mrsrf-pq to directly accept the results of hashbases output instead of reading it from a file, the current setup (which will be impractical once hashbase becomes a function in mrsrf-pq). December 2013Week of Dec. 2-Dec.9: The segmentation fault took a long time for us to fix. We traced the error through several parts of the code looking for something that was trying to access a non-existent memory location. We soon noticed was that a token value was set to 'null'. We thought that this might be a problem, so Dr. Matthews helped us rewrite the code by tokenizing everything, instead of using the strtokr method. This did not work, and eventually we discovered that we HAD to use strtokr, so we changed the code back. It turns out that our update was not able to support concurrency, which defeated much of the purpose of MrsRF. When this did not work, Dr. Matthews encouraged us to go back and look at the Phoenix paper again to see if there was something obvious that we were missing...and indeed there was. We had been using the wrong combiner type. When we first started converting code, we used a lot of ideas from the Word Count code. This code used sum-combiner, because it had to store the sums of the data inserted into it. When we tried to use this same combiner for MrsRF, it did not work. By changing it to buffer-combiner, which buffers all emit values until the reduce function is called, we were able to resolve the segmentation fault. After fixing the segmentation fault, Dr. Matthews helped us examine the outputs and compare them to the original MrsRF's results. As a result, we found an error in the splitter function. The splitter was supposed to break up the two file names (p and q) and output two sections with each file's information. When we ran our code, however, there was only one section. Upon further investigation, we discovered that our statement that determined where we should split information was not set up properly. We fixed this error, and after a brief encounter with an infinite loop, we were able to run the code. After fixing these two major errors, we were able to compare the old and new code. We used print statements to compare results, and found them to be the same. So far we are on the right track! November 2013Week of Nov. 25 - Dec. 2: For the first time last week, we were able to compile Phase 1 of MrsRF without generating any errors. At the time that we compiled, the main method consisted of a simple println "Hello World," so we did not get the desired information, but it lets us know that up to this point, everything is being called correctly. After celebrating for a couple of minutes when we saw "Hello World" pop up on the screen, we began looking at the old version of MrsRF to see what we needed to keep and what we needed to change in the new version's main function. We gradually copied over the code, compiling periodically to make sure we could keep track of and take care of any errors that came up each time. Most of the time it was a simple error, like forgetting to declare a variable. The most recent problem we encountered was a 'segmentation fault - core dump,' which we have yet to fix. We currently have a segmentation fault occurring on the call to the run() function (at the bottom of the main method). The run function is defined from lines 200 - 220 in map-reduce.h and on line 219, there is a return call to a 3-parameter run function (defined directly below the 1-parameter function). Inside the 3-parameter function, the source of the error is on line 252 - the "run-map((ampersand)data[0], count)" line. The run-map function does not seem to be defined in map-reduce.h, which is what we think is the source of the error. We are currently working on finding where the run-map function is defined. Once we find it, we can try to fix whatever is wrong with it. Week of Nov. 19 - Nov.25: We are getting to the point where we are making finer adjustments to the code. The shell of all of the methods we need is there, now we are working on making sure all of the parameters and their types are correct so that the proper information is being passed between each method. We did a lot of work on the class definition/template this week. We looked carefully at each of its parameters and discovered that several of them needed to be changed (wc-string, wc-word) to fit our specific application of the Phoenix Map Reduce program. We also had to find a way to 'trick' the program into accepting the void* casts used in the emit-intermediates function. Every time we fix an error ten new ones seem to appear. To fix a related error in the combiner, we used 'ad hoc polymorphism.' We overloaded the += operator in int-vals-array-t. We still have to work out some kinks in this change (we are still getting an error). Hopefully we will be able to resolve this issue with some more work on the overloaded operator. Our other option is to create our own combiner, which would be time-consuming, and time is not a luxury we have at this point. Assuming there are no more errors once we fix this, we will turn our attention toward actually trying to run the updated code next week. Another of our focuses for this upcoming week will be to look for 'fossil code' -- code transferred to MrsRF++ from MrsRF 1-1 that is no longer necessary/used. One method we have in mind is 'myStrCmp.' We will comment out the method in the code and then run it to see if any more errors pop up. If not, then the method is not called in the program and can safely be removed. Week of Nov. 12 - Nov.19: We compiled the makefiles from all of the different directories into a single file in the MrsRF++ directory by copying and pasting the pertinent code. We encountered a few tricky bugs in one of the include statements (we had misspelled one of the words) and one of the file names (we called it a .cc instead of a .cpp file). Other than these few issues, the work proceeded smoothly as a result of our work with the word count makefile last week. Once we got the makefile working, it was a lot easier to see what we needed to update in the MrsRF++ file. We fixed several errors by adding missing 'declarations' and 'includes' to the file, as well as several of the missing functions (like strcmp) that were originally 'out of the scope.' By using the Make file, we were also able to fix many of our mistakes in the method signatures. It told us that the TreesMR class had too many parameters (7) when the template called for only 5. We are still working on fixing a few more 'not in scope' errors, but the Make file helped us make a lot of progress on Phase 1. Once we complete the Phase 1 update, we will have to run it and compare its outputs to the original MrsRF outputs to see if they match up. Week of Nov.4 - Nov. 12: Updating Splitter Function (Rosemary and Bryce): We worked together on how to update the splitter function. We looked at both versions of the WordCount example and used that as our basis for changing from the old MrsRF to the new. We had to change the breaking points because the WordCount example breaks on several characters while MrsRF breaks only on a new line. We also realized that we needed to make sure that the function signatures match up with what is outlined in the header files. We had to change the names of the functions (splitter to split, map1 to map, for example) and figure out how to adjust to the new parameters. There are still a few things to work out before we can run the code for the first time. In the meantime, we worked on copying several more critical files into our repository: the hashbase and make files. Hashbase is necessary because MrsRF-pq calls and depends on it for its calculations, and the make file is necessary to compile the code. Copying the make file was not enough though. As it was, there were several make files at different levels in the directory. Creating the MrsRF map function (Nathaniel, Lisa, Jorge): This week, we created a MrsRF map function (for map1) that will work with Phoenix++. It is very closely related to the original MrsRF map function, with the primary changes occurring with the parameters passed into the function. Since this map is primarily concerned with calling Hashbase and formatting the results, We do not anticipate seeing a large speedup on this section of MrsRF since we will not be taking advantage of Phoenix++ at this time. This situation may change once we move hashbase from a separate executable to a part of mrsrf-pq. We created a single word count makefile. The original word count used several makefiles, so combining them gave us a little familiarity with how makefiles work. Although this process should have been simple, we ran into a problem when our new makefile kept throwing errors. We could not figure out the source of the error, and ended up undoing all of our changes. However. we still received the same error when we tried to run the original code. We ended up replacing this file with the original makefile from the original download of Phoenix++. This change did not throw this error when run, so we went ahead and made the same changes we had initially made to the makefile. This time it worked without any problems. We still do not know what caused the error that wasted three hours of our time. We updated mrsrf-mpi to C++. As anticipated, this was a straightforward exercise. However, it has not yet been tested since there is no updated mrsrf makefile. I expect any issues to be trivial. TopOctober 2013Week of Oct. 29-Nov.4: We were a little stumped about where to start altering the code, so Dr. Matthews suggested that we print the Phase 1 output and comment out all of Phase 2 to eliminate unnecessary clutter. We added a loop in Phase 1 that printed out each of the bipartitions and its list of values. This output will be useful in the future as we try to test the new MrsRF code (we can compare the Phoenix 2.0 output, which we can assume to be correct, to the Phoenix++ output to see if they are the same). Dr. Matthews helped us zero in on the most pertinent differences between several of the examples in Phoenix 2.0 and Phoenix++. By analyzing these differences, we found that a way to start changing the MrsRF code is to make a whole new file with all the header files. This will act as a framework for us to move forward with. We created this shell program with all necessary header files. This task was slightly more complicated than we had anticipated. We first had to identify all header files used for Phoenix++. Although map_reduce.h is the main header file that appears in the sample applications, it turns out that this header file actually uses other header files. Another challenge was copying over the header files into the MrsRF folder. Since the files were located on a different account, it was necessary to use sudo. However, we completely forgot that I needed to do this and spent an hour trying to figure out why we could not copy the required header files. Next, we will work on making MrsRF more modular by adding at most 2 classes (one for each phase), and then make a MR (map reduce) object called 'mapreduce.run'. We will see how far we can get with this advice! We worked a lot more with Git this week. After recloning our repository onto the new accounts, we practiced fetching, merging with 'newBranch', and then pushing as a way of modifying the master repository. The command to merge is 'git merge origin/newBranch', with 'newBranch' acting as the file that is being merged to. We also learned that after pulling a new version of the code from the master repository, it is necessary to compile/make the hashbase folder and the src folder again. Week of Oct. 22-29:
Investigating Phoenix++ Implementation (Lisa, Nathaniel, and Jorge): We worked closely with Lisa and Jorge this week. We focused on gaining an understanding of the implementation of Phoenix++ and how it differs from Phoenix 1.0. Understanding these concepts is vital for success next week when we begin the actual implementation of Phoenix++ in MrsRF. One of the key differences we noted is that implementations of Phoenix 1.0 require the user to set many different environmental variables, but Phoenix++ streamlines this process extensively and only requires the user to define several functions. The three main functions that the user must redefine are split, map, and reduce functions. Phoenix 1.0 also required these functions to be implemented, so we do not have to concern ourselves with figuring out how to create the appropriate algorithms for these functions. Although the implementation of Phoenix++ does not appear too difficult, we certainly anticipate challenges along the way. In particular, identifying and removing all references to the original Phoenix prior to implementing Phoenix++ will be challenging since they are scattered throughout the code. Investigating Differences Between Phoenix++ and Phoenix 2.0 (Rosemary and Bryce): As we investigated the differences between Phoenix 2.0 and Phoenix++, we discovered that there are some variations in how/where they use combiners and the kind of "containers" they use. The paper we read also described Phoenix++ as more "modular," which is a feature that apparently allows the user to more easily customize the program to meet her specific needs. Developing Test Cases (Rosemary, Nathaniel, and Bryce): We also came up with several ideas of how to test MrsRF. First, we will ensure that the program writes a 'node0.txt' file and contains a TxT matrix of integers. We will also create simple trees that we can solve for by hand and compare our answers to the output from the program. If they match, it is likely that the program is running correctly. By printing the outputs from each phase, we will be able to track the stages that the program goes through. To test the program, we will need to find an efficient way to generate a large number of test trees. Week of Oct. 14-22:
Exploring MrsRF-pq (Rosemary and Bryce): Our work combing through the MrsRF paper really paid off when we were explaining mrsrf-pq. We described what happens during the two map and two reduce phases, and we also created some helpful diagrams to show. Reading the paper helped us to decipher the code much more easily. Exploring Hashbase (Lisa, Nathaniel and Jorge): Hashbase was difficult to understand because there was widespread use of predefined functions, abbreviations, and very few comments to explain their use. Therefore, when our team updates MrsRF we want to be sure to leave many comments behind so that future editors can understand the purpose of each block of code. Despite this setback, we were able to understand the program by identifying individual functions and trying to explain their use, and then looking at the big picture after we understand the various smaller frames of reference. We presented our analysis of Hashbase at the 15 OCT meeting. By listening to CDTs Betros and Tyson's presentation of mrsrf-pq and Dr. Matthew's comments, we have a better understanding of MrsRF 's individual functions and their interplay. This understanding has better prepared us to move forward with code revisions Plan of Attack (Everyone): There were two main parts to our development of the plan of attack. First, we needed to identify the specific tasks that we needed to do. This task required us to get a fairly good vision of what the endstate of the project should look like in addition to gaining a better understanding of the different components of MapReduce and Phoenix. Our work over the past month got us to the point where, with a little help, we were able to specifically identify what needed to be done. In this case, we were able to conveniently break the project up into four different phases. The second part of our planning was more challenging, as we basically had to guess how long it would take us to accomplish each of these tasks. Considering the work that we have already done, our relative familiarity with the code, and the professional opinion of Dr. Matthews, I believe that we came up with reasonable estimates. We will see just how "reasonable" they were in time. Week of Oct. 7-11:
Exploring MrsRF-pq (Rosemary and Bryce): Dr. Matthews returned on Monday. Although she would have been available through the internet, it is still better to have her back so that we can ask her our millions of questions in person. When Bryce and I told her that we were struggling to understand the MrsRF-pq.c code, she suggested that we actually run MrsRF on one of the sets of trees that she had provided to us. Because of all of the lines printed by the code while the program was running, we were much better able to figure out what was happening at each stage. She also suggested rereading the MrsRF paper. When we did, we were pleasantly surprised to find an extremely detailed breakdown of the MrsRF-pq map and reduce phases. When we read the paper the first time, none of this information had made sense, but when we read it this time, after having perused the code for a while, we had a deeper level of understanding. We explained the experience to Dr. Matthews, and she pointed out that it is usually a good idea to read research papers more than once throughout a project, because as you move forward you learn more about the subject and can get more meaning out of the information. We were also able to understand it better when we compared it to the WordCount example. Once we figured out that the bipartitions were the equivalent of the words, everything else fell into place. We now understand what each method/phase takes as input and what it was outputs. Based on the graphs Jorge made from the data Bryce and I generated using our script, we saw that the new machine displayed the expected bahavior when running the WordCount example on files of different sizes. We compared the performance of Phoenix 2.0 to that of Phoenix++, and as we had expected (and as had been reported in the MrsRF paper), we found that Phoenix++ was, on average, 5x faster than Phoenix 2.0. The speed-up was much more pronounced when more cores were used, indicating that Phoenix++ is much more efficient at dividing up the work initially than the earlier version. Exploring HashBase (Lisa, Nathaniel and Jorge): This week we learned about Newick formatted trees. The concept was relatively easy to grasp, and we were able to create five Newick trees after about an hour of investigation. However, we did not realize that Hashbase only accepts binfurcating Newick trees. As a result, the five trees we created were all multifurcating, and therefore caused issues when run in Hashbase. Although it would produce some output, it was not the standard output expected from the trees. After meeting with our advisor, we understood this issue and edited the trees we had produced in order to change them from multifurcating to bifurcating. After this change, Hashbase produced the expected results, showing which trees could have each bipartition. We created a presentation on Hashbase to present to the other members of the team. In creating a presentation for our advisor and the other cadets on the team, we gained a much better understanding of how Hashbase functions. One particularly important insight was the optional seed gained from the command line argument. We initially had trouble understanding how Hashbase could produce the same bipartition IDs when run on different cores since every time we ran the program with the same inputs, Hashbase produced different values for the bipartition IDs. However, we were not using the optional seed parameter and did not consider the fact that MrsRF could call Hashbase with a certain seed value to produce the same values for the bipartition IDs on different cores. This situation also explained the need to pass Hashbase the entire tree file on every core in addition to the portion of the file it will be operating on. The bipartition ID is calculated through the use of a random generator, but the seed value and the entire tree file cause the random function to produce the same values for each bipartition every time it is run. TopSeptember 2013Week of Sept. 30 Oct. 4
Benchmarking Wordcount performance on the new machine (Rosemary and Bryce): We were able to log into the new machine using the new ip address without any problems. It's really cool to watch the screen to see how much all of the processors are working. Dr. Matthews was determined to continue helping us with the research process. We will still meet (but virtually) on the first Day 1 of every week to update her on our status, and we will also continue to send her weekly reports, journal entries, and other deliverables by email. We fixed up the script so that now it will run 5 trials for each number of cores (1, 2, 4, 8, and 16) for each of the different-sized files (10, 50, 100, 200, 500 MB, and 1 GB). We tried to find a way to make the program loop through all of the files in a directory, but had some trouble, so we made a loop for each of the files instead (there are a total of 6 loops in the program). Although it is not the most graceful coding, it did what we wanted it to do, and if we have time, we can try to figure out how to make it more efficient in the future. We successfully copied all of the necessary files from the old machine to the new machine. Using our improved bash script program, Bryce and I were able to run all 5 trials for all the necessary numbers of cores on all of the text files at once. It took a long time for the program to run because of all the work it had to do at once but it was a lot easier to just sit and wait as opposed to having to enter the desired number of cores and which text file we wanted to run the program on for every single trial. The time results were outputted. Benchmarking Wordcount performance on the new machine (Lisa and Nathaniel): We worked together to produce a bash script that ran the necessary tests. In addition to outputting the timing results of the Linux time module for mpirun tested on various core/tree combinations, our script also saved the terminal output, despite our efforts to excise the necessary data points from the text file. Although we were not able to fix this problem, we did learn a lot about I/O operations in bash, especially output redirection, through this experience. We will continue refining the script (probably using Linux's grep functionality, as Dr. Matthews suggested) and make a script to calculate and graph speedup values for mpirun and hashbase in the following week. In addition to continuing to learn about HashBase, we did some investigation into how pointers work in C and C++, since this seems to be fairly important in the creation of the hashtable by hashbase and in how tasks are allocated to different cores in mpirun. We met over the weekend, and we brought each other up to speed on our observations about hashbase. We plan to move forward this week by producing a flow diagram for the function. Graphing benchmarking results and learning about HashBase (Jorge): Hashbase is easily the most different coding language that I have worked with. Unfortunately it is not coming to me intuitively so I will have to work closely with the rest of the team. Week of Sept. 23 27
Analyzing the MrsRF-pq code (Bryce and Rosemary): We looked through the entire MrsRF-pq.c file and used Microsoft Visio to create a diagram of all the major methods in it. We then drew arrows to indicate which methods called other methods. The 'Main' method is the most important, with calls to mrs-rf-reduce1, mykeyvalcmp2, mrs-rf-map2, mrs-rf-map1, mrs-rf-partition2, mykeyvalcmp, compute-number-row-col-trees, and mrs-rf-splitter. This is evidently the function that does the bulk of the work in the MrsRF program. It combines all of the little programs to split, map, and reduce the input. There are four other methods in the file that do not seem to get called anywhere (print-hash-line-from-reduce, print-hashbase-output, print-global-hashtable, and print-local-hashtable-map2) that we believe were used for debugging purposes After a basic bash crash course from Dr. Matthews, we set out to try to automate our testing of the phoenix files in order to make future benchmarking more convenient. Originally, we had trouble getting the output from the time function into our text file of results, but we learned (with some help) that this output came through stderr as opposed to stdout. We were able to figure out how to redirect both outputs into our text file. Additionally, we ran into some problems as we tried to produce a simple, working for loop - we solved this with some quick online searches and with the insertion of a dollar sign before our loop variable. Analyzing Hashbase (Lisa and Nathaniel): After further difficulty understanding hash base, we tried a different tactic: we treated the code like an essay. We first skimmed the code, annotating major and subsidiary functions. We then focused on how the functions supported each other and made additional annotations to clarify the purpose of some of the statements about which I was unsure. Then, we "summarized" the document by writing what, in general, the code on each page of the hashbase printout accomplished. Looking back at our work, there's still a lot of blank space where we weren't sure what comments to make to guide our reading (mostly in the sections where the bitstring operations occur) but we made a lot more progress in a much shorter time span than the hours we spent banging my head again a metaphorical wall last week. Let it never be said that the principles of literary analysis do not apply in computer science! Moving forward from here, we should get down into the fine print of the Newick tree parser and the bitstring computation, look more in depth at TreeZip and identify any differences in how the trees are stored which might impact the content of hashbase, and start preparing a list of recommended changes. September 16 - September 20, 2013
Getting WordCount to work in Phoenix ++ (Bryce and Rosemary):
When Bryce and I graphed the results of our testing, Dr.Matthews was a little bit concerned because one of the bars on the graph was lower than what we had expected. In an attempt to determine the cause of the anomaly, she asked us to run the program using NUMPROCS instead of NUMTHREADS as wehad been before. To address the concern, Bryce and I ran several tests on one text file. We held NUMPROCS constant at 1 for 1, 2, 4, and 6 NUMTHREADS. We then raised NUMPROCS to 2 for 1, 2, 4, and 6 NUMTHREADS. We continued this pattern until we reached a NUMPROCS value of 4. When we reviewed the results, it was clear that NUMPROCS did not affect the speed of the program after all, so we continued to work with NUMTHEADS. Investigated MPI Bindings in MrsRF (Nathaniel):
Investigating HashBase (Lisa):
Improving the Graphing Script (Jorge):
September 9 - September 13, 2013
Getting WordCount working in Phoenix 2.0 (Bryce and Rosemary):
Working on the Website (Lisa and Nathaniel):
Graphing Performance (Jorge):
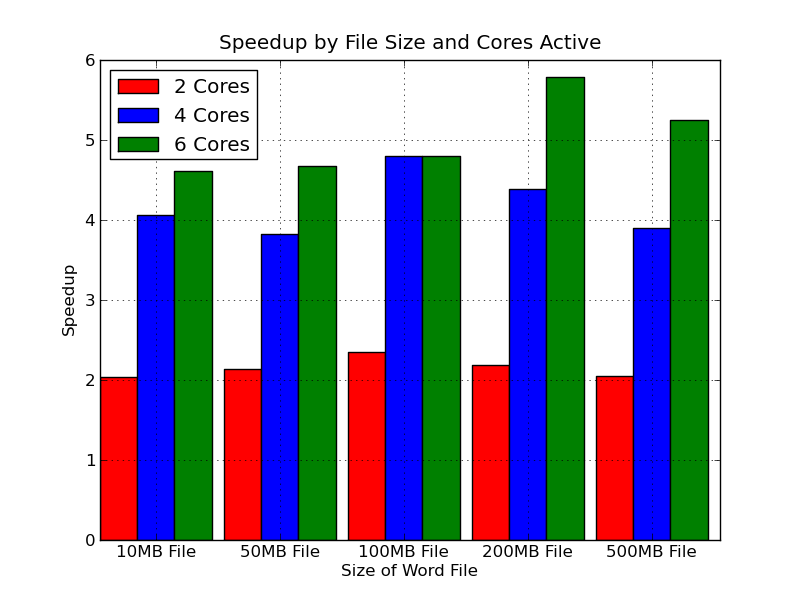 September 1 - September 7, 2013
August 2013August 25 - August 31, 2013 On Tuesday all of us - Rosemary, Bryce, Nate, Jorge, Lisa, and Dr. Matthews - met up in the EECs fish tank (a glass cubicle-like structure) for the "quiz." Dr. Matthews asked us each several questions about the material in the readings. We discussed why phylogenetic trees are important (their applications) and how parts of the software used to analyze the large groups of trees work. Although everyone had done the reading, we all left the meeting with a much better understanding of the work that will be occupying us for the foreseeable future. August 18 - 24, 2013 This week we each met with Dr. Matthews, our project advisor, for the first time and received our first set of tasks for the project. We were to read through the MrsRF and Phoenix MapReduce papers and make sure we could log into the Linux work stations we will be using for our work. Dr. Matthews was eager to see how much we understood about the project and told us to read the papers carefully so we can dazzle her with our knowledge (or at least convince her we have a good idea) of what we are going to be working on when we meet next week. Top |
US ARMY | USMA | EECS | CREU | DR. MATTHEWS' HOMEPAGE
External Links Disclaimer - The appearance of hyperlinks to external sites does not constitute endorsement by West Point or the U.S. Army of the linked web site or the information, products or services contained therein.
Template by bprizze
Copyright MrsRF CREU Team © 2013