In this post, I’m going to walk you through Epiphany’s hello world program,
which can be found in the epiphany-examples/apps/hello-world directory. I
strongly encourage you to see my previous post about the Epiphany architecture
to assist you with your understanding of the material in this post. I will
assume you understand Epiphany’s basic memory model and architecture. This
post was adapted from my slides and lecture notes that I used to teach my
students during the Epiphany unit we had this past semester. This post
summarizes the second lesson in the unit.
Epiphany programming model
Yes, the Parallella people did promise us slick IDE for creating Epiphany programs, but it appears to be largely non-functional, and way too large to be run on the Parallella itself. That’s OK. You don’t need no stinkin' IDE. Let’s do it live!
A few things things to keep in mind before we get started. To program the Epiphany architecture, we need to be mindful of the host/device layout of the Parallella, and the structure of epiphany memory. Recall that we have a host and a device. For every application we write, we must create a corresponding program for each.
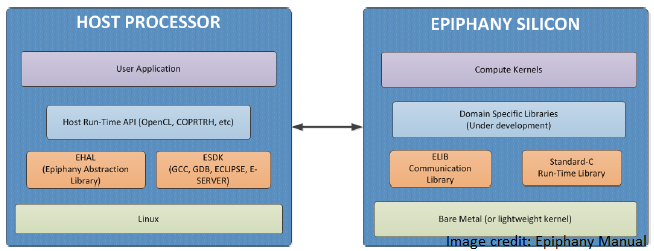
Regardless of whether or not we are choosing to target the Epiphany architecture, all programs and user files are stored on the host (the ARM chip). The host includes the the underlying linux kernel, the main epiphany application (including the source code for the host/device) and other user files, as well as the epiphany software development kit (eSDK) which is a collection of compilers, debuggers and other utilities. While we will be writing separate programs for the host and the device, all the files will be created and stored on the host.
Programming the host
The host program is run on the ARM chip and is responsible for managing/deploying
the device program on the Epiphany chip. Of the two programs, this is the one
that is usually by far the larger. To assist us in creating our host program,
Parallella provides us with the Epiphany Hardware Abstraction Layer (eHAL),
also known as the Epiphany host library. The library is defined in the header
file e-hal.h.
Programming the Epiphany chip
On the Epiphany silicon itself, there are compute kernels, and the Epiphany
Hardware Utility Library (eLib), which is also known as the epiphany
communications library. The eLib provides functions for configuring/querying
epiphany hardware resources. There is also a standard C runtime library, and a
lightweight kernel. When you deploy a job to the epiphany platform, you are
launching a job to a particular Epiphany workgroup.
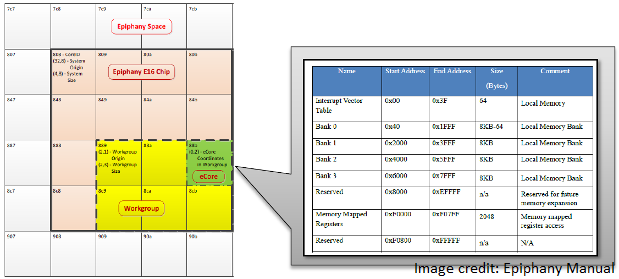
An Epiphany workgroup which is a rectangular collection of adjacent eCores on
th epiphany chip that is defined at run-time by the host program and is
maintained by a workgroup object. A particular eCore member of workgroup is
referenced in terms of the row,col coordinates relative to the workgroup.
Thus, the first core in the workgroup is referenced by (0,0).
At the end of the program run, the workgroup is freed. While you can allocate many workgroups that each run their own separate programs, it is important to note that it is up to the programmer to ensure that that no two programs are assigned to the same workgroup.
Hello World!
Recall that all Epiphany applications must have a separate host and device
program. We will start by examining the hello-world application located in
epiphany-examples/apps/hello-world/src.
The device program: e_hello_world.c
Let’s start by examining the Epiphany device program (e_hello_world.c),
which is shorter and simpler to understand:
|
|
This looks very similar to a regular C program with a few notable exceptions. Let’s trace through this code line by line:
- We are including the new header file
e_lib.hon line 4. - On line 6, we declare a buffer (
outbuf) of 128 bytes that is located in the global memory (shared dram). TheSECTION()function is used to either allocate or access memory from a particular area of memory. - Line 9 identifies a core in the system. Recall that each core has a unique
number that is associated to the cores coordinates in the 4 × 4 interconnect
mesh. The code id is a 12-bit number where the first 6 bits correspond to the
core’s row coordinate and last 6 bits correspond to the core’s column
coordinates. We use the function
e_get_coreid()to access that particular core’s core id. Note that this function takes no parameters. - On the next line, we use the
sprintf()function to write to outbuf our particular hello world message, which is formatted with the core’s id. - Lastly, we return the flag
EXIT_SUCCESSto indicate that we finished succesfully.
The host program: hello_world.c
The host code is a bit more complicated. Recall that the purpose of the host is to supervise the work of the device, including transferring data to and from the device. Remember that the device cannot do memory fetching or I/O on its own. Many of the functions you see in the host program reflect that aspect of the architecture:
|
|
We will attack this code section by section. Let’s start with the headers and definitions:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <e-hal.h>
#define _BufSize (128)
#define _BufOffset (0x01000000)
#define _SeqLen(20)
- Recall that the header file
e-hal.hdefines the functions in the Epiphany library API. - We define three constants using the define directive. Whenever possible, it is good to use the define directives when dealing with epiphany code, since these values are set at compile time. The three constants we define here respectively define the size of the buffer, the location the buffer will be placed in epiphany memory, and the number of cores we will query.
Let’s move our discussion to the first few lines in main():
int main (int argc, char** argv) {
unsigned row, col, coreid, i;
e_platform_t platform;
e_epiphany_t dev;
e_mem_t emem;
char emsg[_BufSize];
srand(1);
e_init(NULL);
e_reset_system();
e_get_platform_info(&platform);
After we declare our variables as per normal, we declare three new variables of special type:
- The first,
platform, is of typee_platform_tand stores the platform information of the epiphany device. - The second variable,
dev, is of typee_epiphany_tand stores information on the eCore workgroup.
Recall that the eCore workgroup is a rectangular mesh of eCores that is allocated to perform a particular task. It is up to us to ensure that no workgroup is performing more than one task, but that is not something we have to worry about in this example.
- Next, we declare a variable called
ememof typee_mem_t, which will be used to help us keep track of memory on the eCores. - Lastly, we allocate a buffer called
emsg, which will store the message that will be received from the epiphany eCores.
The next three lines initializes the device.
- We first call
e_init(), which initializes the host library data structures and establishes a connection to the epiphany platform. - The next function,
e_reset_system(), performs a full hardware reset of the Epiphany system. e_get_platform_info()gets the information on the epiphany platform, and stores is in the the platform variable.
In general, these three lines are run at the beginning of all epiphany programs. When you design your own Epiphany programs, be sure to include it!
Let’s move on to the heart of the application:
e_alloc(&emem, _BufOffset, _BufSize);
for (i =0; i<_SeqLen; i++) {
row = rand() % platform.rows;
col = rand() % platform.cols;
coreid = (row + platform.row) *64 + col + platform.col;
fprintf(stderr, "%3d: Message from eCore 0x%03x (%2d, %2d): ", i, coreid, row, col);
- The first function,
e_alloc(), allocates a segment of epiphany memory. It takes a reference to epiphany memory (emem), the location with which to reference the memory, an offset from the external memory base specifiying where the memory should be allocated, and the size of the allocation. Subsequent accesses to this place in memory will be done using theememobject. - Next, we start a loop that is
_SeqLenlong (20for now). - We use the
rowsandcolsattributes of theplatformobject to reference the number of rows and columns respectively, and use that to generate a random row and column. - We next calculate the core id (
coreid). Recall that the core id is a 12-bit number, where the 6 most significant bits represent the row location, and the last 6 bits represent the column location. - The variables
rowandcol(somewhat confusingly named) specify the row of where the east/west control registers lie, and the column of where the north/south control registers lie. You don’t have to worry about these too much for now; in the context of this program, we are just using them to help us perform the math necessary to calculate the core id. - The
fprintfstatement (which goes tostderr) prints out the starting part of the string, which identifies the core that the message is coming from, and its position in the mesh.
e_open(&dev, row, col, 1, 1);
e_reset_group(&dev) ;
e_load("e_hello_world.srec", &dev, 0, 0, E_TRUE);
usleep(10000);
e_read (&emem, 0, 0, 0x0, emsg, _BufSize);
fprintf(stderr, "\"%s\"\n", emsg);
e_close(&dev);
}
The next two lines prepares the workgroup for handling the job:
- The function
e_open()defines a workgroup (referenced bydev) starting at positions marked byrowandcolof the sizes specified. In this case, we want the workgroup to be defined just around a single eCore. - The
e_reset_group()function performs a soft reset of the group. We never want to perform this operation on a workgroup that is currently doing work, as it can bring the system to an undefined state.
Next, we use the e_load() function to move the object file onto a workgroup
core. The coordinates that follow are relative to the workgroup (hence why it’s
0,0). We then use the flag E_TRUE to indicate that the process should be
started immediately.
-
We then put the host to sleep for 10,000 microseconds.
-
We use the function
e_read()to read from the workgroup’s memory starting at relative row column values with the specified offset, and placing it into the specified buffer (emsgof the specified sizeBufSize). Please note that if you look at the epiphany SDK manual, you will find a different definition – it appears in later versions of the SDK this was changed. -
After this, we print to standard error the contents of the buffer.
-
Lastly, we close the workgroup specified to by
devusing thee_close()function.
The last three lines clean up the program:
e_free(&emem);
e_finalize();
return 0;
}
The function e_free() frees the external memory buffer and e_finalize()
finalizes the connection with the epiphany system.
Compling and Running the Code
Above the src directory in the main hello-world directory, there are two
files: build.sh and run.sh. It is best that you create a copy of these files
and then customize them for all your future applications.
We will study each of these files in turn:
build.sh: compiles the hello-world application
Let’s take a look at build.sh first:
|
|
The first few lines set paths to make use of the Epiphany libraries, and sets
other variables to enable execution. You can ignore the whole CROSSPREFIX
section, since that is for people who are not natively building on the
Parallella board.
Line 27 compiles the host side application. This looks like a standard gcc
build command, with the resulting executable being placed in the directory
Debug/hello_world.elf and linked against the necessary header and library
files.
Line 30 compiles the device side application. The e-gcc compiler looks
similar to gcc, but its job to create an executable that is suitable for the
epiphany architecture. The -T flag is mandatory, and links the created
executable to the board linker file specified by $ELDF. It also links against
the eLib library, which is specified with the mandatory flag -le-lib.
Line 33 is absolutely crucial. The e-objcopy command copies a binary file,
transforming it into a standard S-record (SREC) file in the process, which is
a standard assembly file created by Motorola that is commonly used in
microcontroller applications. Currently, SREC is the only type of file that
the Epiphany boards allow.
run.sh: runs the hello-world application
Let’s now take a look at the run.sh file:
|
|
We set some more paths in the first few lines, cd into the Debug directory,
and run the command on line 11.
Notice that the structure is very similar to the way we ran the JtR program
in our previous post! Recall that programs must be invoked using superuser
priviledges, so the sudo -E is required. The -E flag helps us specify the
environment. In this case, we also need to specify the location of the hardware
descriptor file of the Epiphany board (EHDF).
What’s this program doing?
First, does this program executing in parallel? If you have been following
closely with our example, you should quickly see that the answer is no! Though
the program runs non-deterministically, it is not due to parallel execution.
The random number generator randomly generates random row and col values
which is used to construct a random coreid. That single core is accessed,
and the hello-world application is run on that single core! We can confirm this
by closely inspecting line 28. Note that the size of the workgroup being
created by the e_open command is 1x1, or 1 core. So, we randomly access
a single core _SeqLen times, running the hello-world.srec (device program)
on it serially.
In Class Exercise:
Modify the hello-world application so that it prints out hello world on every core in order. That is, core (0,0) gets printed out first, core (0,1) second and so on, until all 16 cores output the hello-world message. How does the device program change? How does the host program change?